

Have you ever read some article emphasizing how crucial robots and/or robots.txt file are? Perhaps you have not read about it before but you are fascinated by really that online information regarding Spiders, Robots and Crawlers. In this post, you will hopefully comprehend all of these terms and how they make websites crawled and indexed quickly.

Nowadays, although many internet marketers emphatically no longer pay no attention to the robots.txt file stating it is outdated and useless, I still believe that robots.txt file is most likely not that incredibly effective method to promote and maintain your brand-new advertising website within a day, but definitely continues to perform a significant job over time. The robots.txt file is a straightforward method which also allow you to safeguard your privacy and perceptive property. Let's find out what all the mentioned vocabulary mean.

"www robots", on the contrary, are computer programs that instantly scan web pages and pass through every single hyperlink detected so as to accumulate all of the information found on those websites.
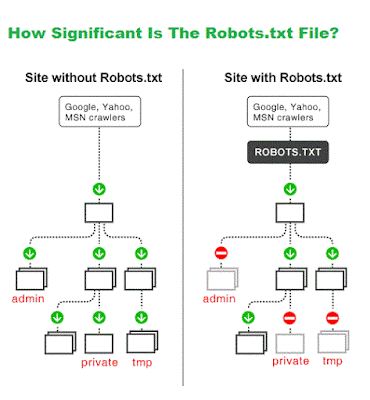 Google, as a highly confidential search engine, has identified so little about the way its protocol functions, how it crawls, looks for terms and establishes its rankings. Actually, you can dig in specific community forums discussing this thing, you will find that no one truly approves if Google mostly focuses on this or that aspect to create its search rankings. So when there is no mutual consent on points as accurate as Google's ranking algorithm, this implies that: either Google is continuously modifying its techniques making it unclear and hard to be figured out, or the secret is behind that robots.txt file on your web server which Google has highly advised to properly use it.
Google, as a highly confidential search engine, has identified so little about the way its protocol functions, how it crawls, looks for terms and establishes its rankings. Actually, you can dig in specific community forums discussing this thing, you will find that no one truly approves if Google mostly focuses on this or that aspect to create its search rankings. So when there is no mutual consent on points as accurate as Google's ranking algorithm, this implies that: either Google is continuously modifying its techniques making it unclear and hard to be figured out, or the secret is behind that robots.txt file on your web server which Google has highly advised to properly use it.
As easy as ABC, use Notepad in Windows, or the simplest text editor in Linux/Mac, input a couple of lines (as explained below) and save it after labeling it robots.txt and transfer it to your server's root where your homepage is.
Those lines can be recurring to leave out all robots or to unindex any file or directory. If you keep the Disallow line unfilled, this indicates you are allowing the specific robot to crawl your whole website. Let's go through some examples to have it nailed down!
Disallow: /private/privatefile.htm
Disallow: /underconstruction/
The directory here is encased by two forward slashes. Notice that a web server is using the ending slash which essential before redirecting to the requested page.
User-Agent: *
Disallow:
User-Agent: *
Disallow: /
The forward slash implies "root", the primary access to your website.
Disallow: /
User-Agent: Googlebot-Image
Disallow: /images_main/
Disallow: /images_family/
Disallow: /downloaded_pictures/
User-Agent: Googlebot
Disallow:
User-Agent: *
Disallow: /
The commands are sequenced which let Googlebot through and prevent any other bot in.
Hypothetically, despite the fact that every robot should conform to the criteria released around 1994 and improved in 1996, but each robot operates slightly in a different way. There are quite a few irregular behaviours of some robots. For instance, some robots allow wildcards in the Disallow line and other actually permit various commands. So, just don't worry about shifting from the common and you will be just fine.
Consequently, we have seen what are robots, robots.txt file, good bots and bad bots, spiders and crawlers and how things work to get your site appropriately indexed in search engines. Let's take a look at things from another perspective! Could we make our own robot program that reads a robots.txt file and particularly check out webpages that we tagged as "disallowed"? Definitely not, this whole standard is depending on everyone's efforts so as to render the online world a better place. Essentially, do not count on this for safety measures or privacy. Make use of passwords whenever required.
To summarize, keep in mind that indexing robots are absolutely important . Whilst you shouldn't create a website for robots but rather for human visitors, do not undervalue the strength of the brainless spiders. Ensure that the webpages you wish to be indexed are properly found by robots. Be certain to have standard hyperlinks that robots are bale to comply with without having any hurdles (robots aren't able to follow Flash based navigation systems, for example). To maintain your website effective, your logs clear and your programs, scripts and private information safe, use constantly a robots.txt file and make certain to go through your records in order to keep track of all robotic behaviour.

Nowadays, although many internet marketers emphatically no longer pay no attention to the robots.txt file stating it is outdated and useless, I still believe that robots.txt file is most likely not that incredibly effective method to promote and maintain your brand-new advertising website within a day, but definitely continues to perform a significant job over time. The robots.txt file is a straightforward method which also allow you to safeguard your privacy and perceptive property. Let's find out what all the mentioned vocabulary mean.
What Do Robots And Robots.txt File Specifically Mean?
Robots (referred to as "bots") are programs that function as agents for an end user or a system, or imitate a human activity. The most common bots online are the programs, known as spiders and crawlers as well, which gain access to Web pages and collect their particular content material for search engine indexes.
"www robots", on the contrary, are computer programs that instantly scan web pages and pass through every single hyperlink detected so as to accumulate all of the information found on those websites.
How About Search Engines, Spiders And Crawlers?
Search engines are programs that read through a repository. In other words, with reference to the web, search engines are regarded as a system having a user lookup form that is able to look through a data source of websites compiled by a robot. Concerning Spiders and Crawlers, they are also robots or bots but with just a different label and their function is not that different than the previous robots we referred to.How Significant Is The Robots.txt File ?
Google has always taught users about the robots.txt file and recommended to utilize this tool due to its importance. Presently, search engines are no longer a test area for researchers and geeks, but rather it is the field of corporate and business establishments.
As easy as ABC, use Notepad in Windows, or the simplest text editor in Linux/Mac, input a couple of lines (as explained below) and save it after labeling it robots.txt and transfer it to your server's root where your homepage is.
What Does A Robots.txt File Contain?
Simply a couple of lines you need to input into a robots.txt file:- The User-Agent that possesses the robot identity you would like to allow requests or the '*' wildcard symbol indicating 'all'.
- The Disallow line, that informs a robot of all the locations need not be modified.
Those lines can be recurring to leave out all robots or to unindex any file or directory. If you keep the Disallow line unfilled, this indicates you are allowing the specific robot to crawl your whole website. Let's go through some examples to have it nailed down!
- Exclude a specific file from Googlebot:
Disallow: /private/privatefile.htm
- Exclude a directory from all robots:
Disallow: /underconstruction/
The directory here is encased by two forward slashes. Notice that a web server is using the ending slash which essential before redirecting to the requested page.
- Allow everything (empty robots.txt):
User-Agent: *
Disallow:
- Excluding any robot on your site:
User-Agent: *
Disallow: /
The forward slash implies "root", the primary access to your website.
- Stop Googlebot-Image from indexing your images :
Disallow: /
- Stop Googlebot-Image from indexing some of your images:
User-Agent: Googlebot-Image
Disallow: /images_main/
Disallow: /images_family/
Disallow: /downloaded_pictures/
- Permit Googlebot crawl only.
User-Agent: Googlebot
Disallow:
User-Agent: *
Disallow: /
The commands are sequenced which let Googlebot through and prevent any other bot in.
Hypothetically, despite the fact that every robot should conform to the criteria released around 1994 and improved in 1996, but each robot operates slightly in a different way. There are quite a few irregular behaviours of some robots. For instance, some robots allow wildcards in the Disallow line and other actually permit various commands. So, just don't worry about shifting from the common and you will be just fine.
Consequently, we have seen what are robots, robots.txt file, good bots and bad bots, spiders and crawlers and how things work to get your site appropriately indexed in search engines. Let's take a look at things from another perspective! Could we make our own robot program that reads a robots.txt file and particularly check out webpages that we tagged as "disallowed"? Definitely not, this whole standard is depending on everyone's efforts so as to render the online world a better place. Essentially, do not count on this for safety measures or privacy. Make use of passwords whenever required.
To summarize, keep in mind that indexing robots are absolutely important . Whilst you shouldn't create a website for robots but rather for human visitors, do not undervalue the strength of the brainless spiders. Ensure that the webpages you wish to be indexed are properly found by robots. Be certain to have standard hyperlinks that robots are bale to comply with without having any hurdles (robots aren't able to follow Flash based navigation systems, for example). To maintain your website effective, your logs clear and your programs, scripts and private information safe, use constantly a robots.txt file and make certain to go through your records in order to keep track of all robotic behaviour.



0 Comments:
Post a Comment